
We partnered with Databricks to benchmark SQLMesh against dbt Core™ on key transformation tasks — and our tests showed that SQLMesh outperforms dbt by 9x in both speed of execution and compute cost. Read the full study to see why SQLMesh (and our hosted solution, Tobiko Cloud) are the efficient, future-proof, and smarter alternatives to dbt for data engineering.
Updated on June 7, 2025: This blogpost was amended to reflect time and cost saving projections from running transformation tasks on SQLMesh versus dbt Core, based on revised assumptions regarding warehouse size, team size, and the number of transformation changes typically made by data engineers.
Tobiko is redefining speed, efficiency, and the developer experience in data engineering
Our team at Tobiko is setting a new standard for developer experience with data transformation. We founded our company to tackle fundamental shortcomings in how conventional tools handle data engineering queries and operations. At Tobiko, we’ve built a platform that rises to the challenges of the modern data stack. Designed with state- and time-aware architecture, semantic understanding of SQL, instant and proactive error alerts, and the ability to replicate and overwrite production data in low-cost virtual environments, our products—SQLMesh and its hosted, enterprise-ready version, Tobiko Cloud— are future-proofed for any level of complexity and scale.
To illustrate how our features can drive transformative improvements in efficiency and productivity across end-to-end data engineering processes, we partnered with Databricks to conduct a benchmark study. Using Databricks as the warehouse, we compared the cost and speed performance of our open-source transformation framework, SQLMesh, against that of dbt Labs’ open-source counterpart, dbt Core™. We tested four integral operations to every data engineer’s workflow — creating development environments, handling breaking changes, promoting changes to production, and rolling changes back.
Our choice of benchmark is intentional. dbt Labs established the market standard for data transformation — and many of the architectural decisions that make SQLMesh what it is today trace back to the innovations dbt had pioneered. dbt has profoundly shaped the industry — before dbt, business logic was trapped in BI and reporting tools, making pipelines nearly impossible to test, debug, or version control. By implementing a git-based workflow for SQL transformation, dbt instilled more discipline into how data teams treat transformation. It elevated business analysts to analytics engineers and installed guardrails for data consistency.


But the data space is evolving. The meteoric rise of AI/ML applications introduced an explosion of data sources, formats, and volume — and tools designed for conventional norms of data transformation are being stretched beyond their limits. Data teams are no longer operating within neatly contained worlds of single warehouses and engines — they are navigating sprawling data stacks, byzantine dependency graphs, and ever-expanding scale.
This is the reality that led to Tobiko. In many ways, we are fortunate to have built our products at a time when the demands of the post-modern data stack are taking clear shape. dbt laid the groundwork for data transformation, and we are elevating the bar it set to meet the surging complexity and evolving needs of data engineers today.
What is SQLMesh — and what makes us the better dbt alternative?
Tobiko was founded in 2022 to reinvent how teams can transform data. We created two open-source frameworks, SQLGlot (for SQL parsing and transpiling) and SQLMesh (for data transformation and modeling). Tobiko Cloud is our flagship cloud platform, built on top of SQLMesh. It’s a managed solution for data teams to run, orchestrate, and collaborate with ease on their most critical data pipelines in production.

Three key features differentiate the data architecture of Tobiko’s products from those of dbt — virtual data environments, column-level lineage, and state awareness. These features power the stark performance differences between our tools, as we demonstrate and explain in our benchmarks below
Our benchmarking approach: Comparing SQLMesh and dbt Core™ head-to-head
For our benchmarks, we evaluated four distinct tasks that data engineers routinely perform along an end-to-end workflow. To ensure a meaningful, apples-to-apples comparison, we identify for each task the corresponding actions needed to implement it in both SQLMesh and dbt Core. For more details on our benchmark setup, refer to the footnotes at the end of this article.1
We selected the following tasks to benchmark:
- Creating a development environment
- Making a breaking change (e.g. updating an existing column)
- Promoting changes to production
- Make a change to a model, and reverting that change after promoting to production
Spin up development environments ~12x faster and cheaper in SQLMesh vs dbt Core
The first step of the developer workflow is to create a development environment. Below is an overview of how this is done in dbt Core and SQLMesh, respectively.
In dbt Core — we ran the following command:
dbt run
With dbt Core, users set up a development environment that is linked to a schema in their database. To begin development, they must run dbt, which triggers a full rebuild of their dev schema. This comes with a significant drawback — users must go on standby as their entire data warehouse is physically rebuilt before they can move forward. The lag disrupts the developer experience, forcing delays that can scale exponentially with the size of the model. It also exposes users to the risk that their development schema may turn stale while they are waiting for the warehouse to recompute.
In SQLMesh — we ran the following command:
sqlmesh plan dev -–include-unmodified
With SQLMesh, we spin up virtual data environments — virtualized views that layer an exact replica of users’ production data over their physical infrastructure. By virtue of the separation between the virtual and physical layers, data becomes available to users almost instantly. It takes mere seconds to spin up a mirror production, entirely bypassing the delays of a physical rebuild. Not only does SQLMesh’s approach improve speed, but by generating only lightweight views rather than full rebuilds, we minimize the compute costs that dbt Core’s method would incur.
From the outset of the transformation workflow, SQLMesh is off to a substantially quicker and cheaper start, allowing data engineers to begin working in a new development environment at close to 12x faster speed and lower cost.

Process breaking changes 1.5x faster and cheaper with SQLMesh vs dbt Core (and almost 12x faster and cheaper with Tobiko Cloud)
With a new development environment in place, a routine task for the data engineer to proceed to is modifying existing data pipelines. Any such adjustment — for instance, updating a column or aggregation — can ripple through multiple downstream dependencies. Without visibility or a means to predict or preview the potential impact, users may struggle to make changes with confidence.
For this benchmark, we update the projection “iscurrent” from ‘true’ to ‘false’, resulting in a breaking change in the DimBroker.sql model. Here is how this breaking change is handled in dbt Core versus SQLMesh:
dbt Core detects the update, and runs the project (dbt run) with selectors to rebuild all models downstream of the one that was modified. Why all models? The reason is that dbt lacks semantic understanding of SQL, without which it cannot determine whether a change is breaking or non-breaking. In the absence of that distinction, dbt can only assume all downstream models to be affected, and therefore must be reprocessed.


SQLMesh, by contrast, takes a surgical approach. We automatically categorize this change as breaking or non-breaking, by tracing column-level lineage and carrying out impact analysis to identify which downstream models it cascades to. This is made possible by the platform’s ability to interpret SQL at the AST (abstract syntax tree) level. By computing the semantic diff between the current and previous model versions, SQLMesh recognizes which downstream models rely on the updated column, and selectively skips backfilling those that do not.
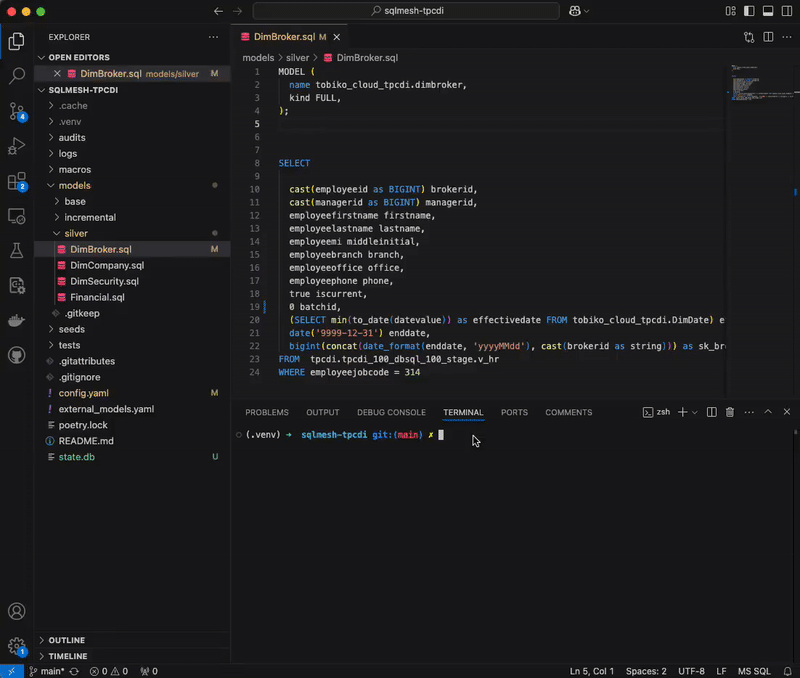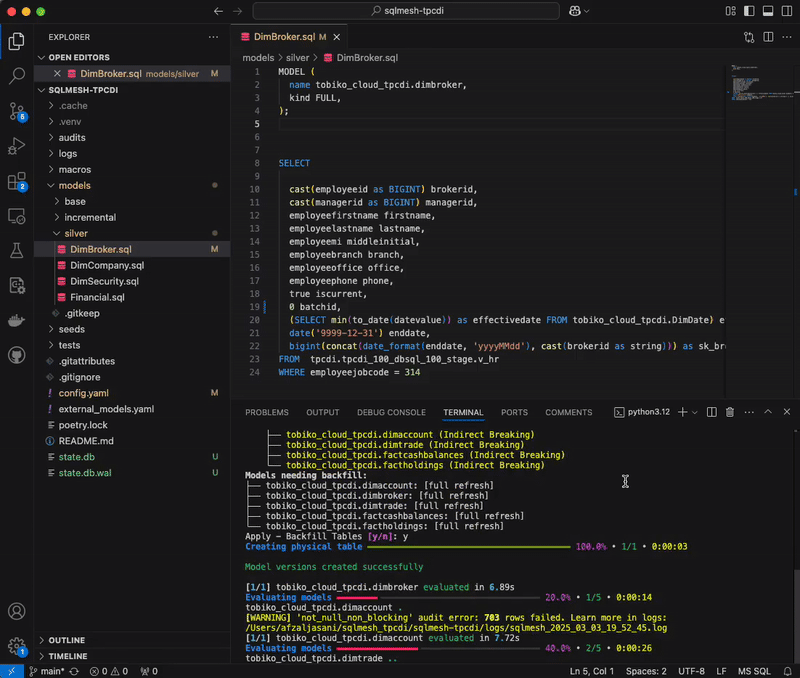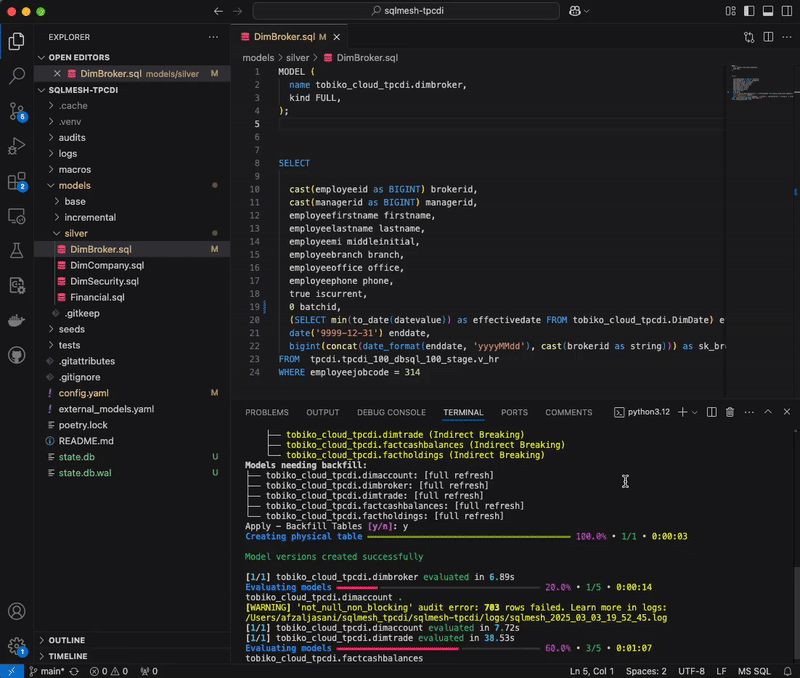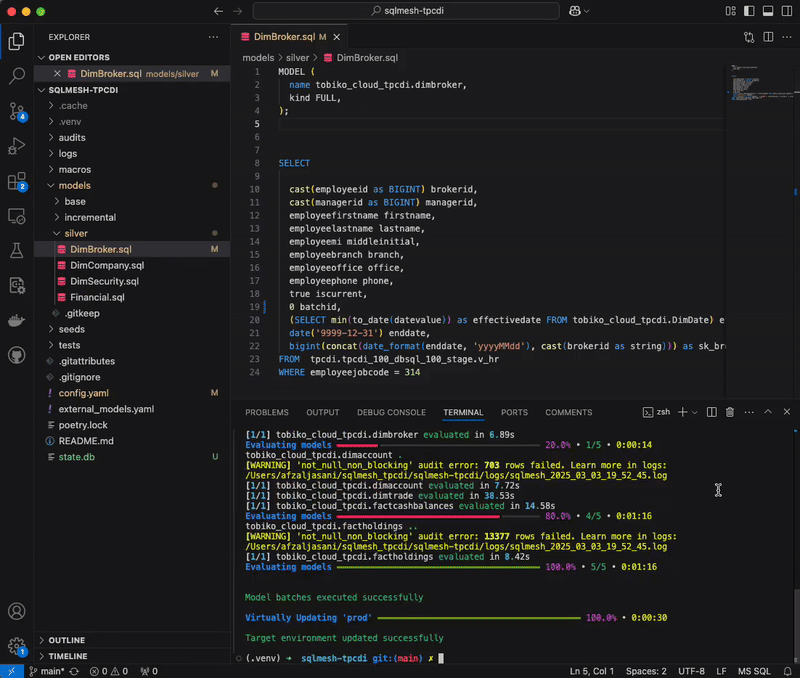

This precision eliminates guesswork for data engineers, giving them the certainty to make changes without feeling like they’re flying blind. It also delivers unmistakable speed and cost advantages. By performing targeted instead of brute-force reprocessing, SQLMesh handled the breaking change 1.5x faster than dbt Core, while using 1.5x less compute.
While this study focuses on benchmarking SQLMesh against dbt Core, we also evaluated Tobiko Cloud, the hosted version of SQLMesh, to examine its handling of breaking changes. SQLMesh uses column-level lineage to differentiate between breaking and non-breaking changes—and Tobiko Cloud extends this capability with more surgical change categorization, refining how downstream updates are processed when a column is modified. This further reduces time and compute spent on backfills, making Tobiko Cloud even more performant than its counterpart—by a factor of seven.

Promote changes to production 134x faster and 123x cheaper with SQLMesh vs dbt Core
In our next benchmark, we assess how a newly made change is promoted to production in each tool.
To promote to production with dbt Core, a data engineer merges updated code into the main branch. From there, dbt Core must re-run the entire data pipeline from scratch. Because dbt Core does not have a built-in function to carry over work that has been done in the development environment, data engineers cannot reuse anything created during testing without extensive custom work through macros and complex, carefully orchestrated dbt commands.
In SQLMesh, on the other hand, deploying changes to production is a virtual layer operation that reuses physical datasets wherever possible. Results observed during development remain exactly the same in production, keeping data and code perpetually in sync. Once a change is committed, a PR is created, and code is merged into the main branch, there is no need for manual orchestration or additional reprocessing - SQLMesh manages these automatically.
SQLMesh gives our users a frictionless, risk-free mechanism to move changes to production. Beyond ensuring more reliable promotions, it accelerates the process by an astonishing 134x, while delivering equally game-changing cost savings (SQLMesh is 123x cheaper) by reapplying existing data and avoiding reruns.

Revert changes from production 136x faster and 117x cheaper with SQLMesh vs dbt Core
For our final benchmark, we examined a crucial step that can take place after promotion to production - rolling changes back. Despite best efforts, mistakes can slip through, leading to incorrect data. In some cases, they go unnoticed until an executive has already reviewed a critical KPI in a dashboard, sending data teams into fire drills to diagnose the cause and mitigate impact.
It is very difficult to revert data pipelines to a previous state in dbt Core. Users may be forced to sift through large numbers of tables and rows to identify and correct the ones that were impacted – a highly manual process of rewriting queries and backfilling records that is both time-consuming and error-prone.
In SQLMesh, each model change is captured in a separately versioned table/view, making rollbacks to previous versions easy and seamless. Our virtual data environment architecture allows users to apply a simple virtual update — without the need for extensive recomputation or hands-on troubleshooting.
As a result, we observed that relative to dbt Core, reverting changes from production in SQLMesh is 117x less costly and 136x faster. These efficiencies go beyond resources saved. The capacity to swiftly and effortlessly roll back incorrect data that has leaked into production is also imperative to limiting its disruption to the data team — and the rest of the business.

At 9x efficiency, SQLMesh scales data transformation beyond dbt Core
Over the past decade, dbt has helped analysts move from spreadsheets to SQL-based transformation, bringing the function from 0 to 1. But as data proliferates and becomes ever more central to business operations, the standard has risen dramatically for reliability and efficiency. Growing scale and complexity demand a more nimble and scalable solution to transforming data - one that legacy paradigms are no longer best equipped to support.
SQLMesh was built for this next evolution in data engineering — and for taking data engineers from 1 to 10. Our benchmarks show that SQLMesh significantly enhances developer productivity while slashing infrastructure costs and operational overhead at every stage of the transformation workflow.
If we assume a team of ten developers, each setting up a new development environment, making changes, promoting them to production, and rolling back errors at a cadence of 30 times a week over a month, the total cost of ownership in SQLMesh is one-nineth that of dbt Core. Beyond savings on compute, this translates to reclaiming 300 hours of data engineering time a month for higher-value work — delivering a disruption-free and next-level developer experience.
Tobiko Cloud further sharpens the contrast, cutting compute cost by a factor of 23. Work that would otherwise have consumed over 338 hours (including delays and reprocessing) can be completed in just over 15. Tobiko Cloud also reinforces this performance uplift with enterprise features in orchestration, advanced observability, and security to support better data governance and operational best practices.

Tobiko — Future-proofing your data transformation
With state awareness, column-level lineage, and virtual data environments, we redefine how data teams interact with their pipelines, removing risks, delays, and redundancies. Unlike dbt Core, which forces teams to choose between easy but expensive rebuilds or complex, error-prone manual selectors, SQLMesh (and Tobiko Cloud) deliver both simplicity and efficiency — without tradeoffs.
For data teams navigating an increasingly vast and intricate data landscape, fast iteration, seamless deployment, and instant error recovery are no longer luxuries, but necessities. SQLMesh is not just a conclusively more efficient alternative to dbt Core, we offer a fundamentally more scalable model for data transformation, one that is purpose-built for the realities of the post-modern data stack, and for evolving with the way data engineers work.
For purposes of our benchmark testing:
- We used an end-to-end implementation of TPC-DI, and a 2X-Small Databricks SQL Serverless warehouse with 1 cluster. However, we extrapolated the cost savings using the assumption that the average medium-to-large data team would be running pipelines on significantly larger Databricks warehouses at a 10,000x scale factor.
- Visit this repo to test and run the same models as they would be executed in dbt Core
- Queries were run one at the time to prevent concurrency issues.
- Benchmarks were run with a hot start to ensure no variance was affected by serverless compute spinning up from a cold start.
- We used the same catalog but separate schemas to ensure proper isolation.
- We used dbt version 1.8 and Tobiko Cloud (Enterprise:202509.63.0+ca2cefd Core: 0.162.2).



