
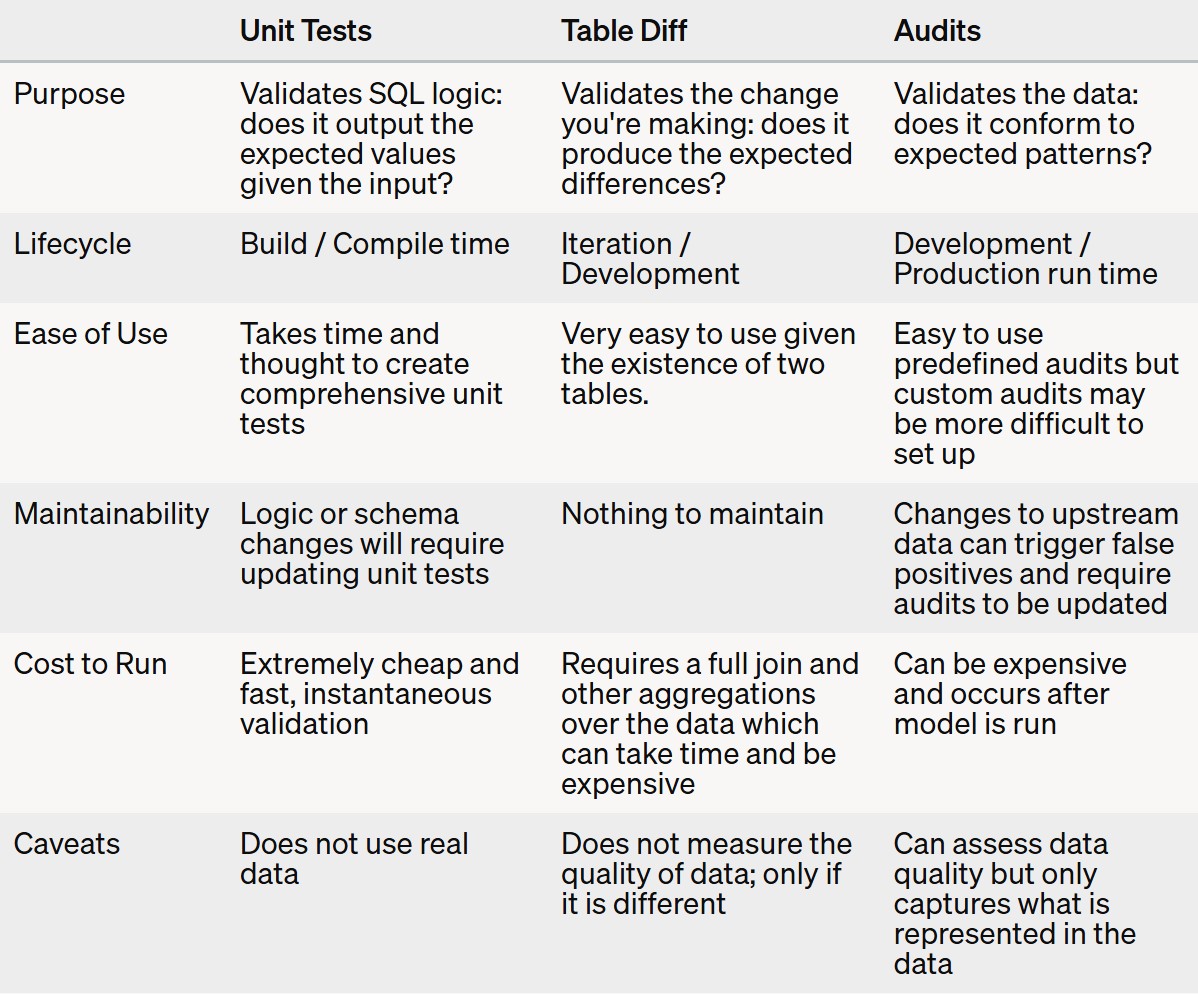
Although companies heavily rely on SQL / data pipelines to power applications and make decisions, testing is usually an afterthought. However, systematic testing of data is critical to creating trustworthy and reliable pipelines. This post highlights the three categories of tests for data: unit tests, table diffs, and audits.
Although companies heavily rely on SQL / data pipelines to power applications and make decisions, testing those pipelines is usually an afterthought. The practice of testing software is well established and considered a critical component of application development. Currently, testing data models is still in its infancy and not as common nor considered as important as testing software.
However, systematic testing of data is critical to creating trustworthy and reliable pipelines. This post highlights the three categories of tests for data: unit tests, table diffs, and audits.
Unit tests
Unit tests are the first line of defense for all software. They ensure that changes to code don't unexpectedly change business logic. They are also great at validating logic and edge cases. As code bases become more complex, it becomes increasingly difficult to test and validate changes manually. Unit tests give teams the confidence to collaborate on changes while knowing that even minor unintended changes will be caught.
In my opinion, unit tests are the most important yet ignored technique for creating robust data pipelines. Unit testing pipelines can be as simple as a script that tests whether or not the output of a SQL query matches a fixed input.
Example unit test
Let's say we want to unit test this SQL query which computes total revenue for users from two upstream tables.
WITH orders AS (
SELECT *
FROM raw.orders
WHERE transaction_type NOT IN ('refund', 'void')
), discounts AS (
SELECT
order_id,
SUM(discount) AS discount
FROM raw.discounts
WHERE status = 'used'
GROUP BY order_id
)
SELECT
o.user_id::INT AS user_id,
SUM(o.total)::INT AS gross_total,
SUM(o.total - COALESCE(d.discount, 0))::INT AS net_total
FROM orders o
LEFT JOIN discounts d
ON o.order_id = d.order_id
GROUP BY o.user_id;You can create fake data for each raw table, execute it, and validate that the results are as expected.
test_revenue:
model: revenue
inputs:
raw.orders:
- order_id: 1
user_id: 1
transaction_type: complete
total: 4
- order_id: 2
user_id: 1
transaction_type: complete
total: 3
- order_id: 3
user_id: 1
transaction_type: VOID
total: 3
- order_id: 4
user_id: 2
transaction_type: complete
total: 2
raw.discounts:
- order_id: 1
status: used
discount: 1
- order_id: 1
status: void
discount: 1
outputs:
# Test the main query
# SELECT
# o.user_id::INT AS user_id,
# SUM(o.total)::INT AS gross_total,
# SUM(o.total - COALESCE(d.discount, 0))::INT AS net_total
# FROM orders o
# LEFT JOIN discounts d
# ON o.order_id = d.order_id
# GROUP BY o.user_id;
query:
- user_id: 1
gross_total: 7
net_total: 6
- user_id: 2
gross_total: 2
net_total: 2
ctes:
# Test the first CTE
# WITH orders AS (
# SELECT *
# FROM raw.orders
# WHERE transaction_type NOT IN ('refund', 'void')
# )
orders:
- order_id: 1
user_id: 1
transaction_type: complete
total: 4
- order_id: 2
user_id: 1
transaction_type: complete
total: 3
- order_id: 4
user_id: 2
transaction_type: complete
total: 2This is an example YAML file in SQLMesh's format that contains a declarative unit test. It specifies fixed input values for raw.orders and raw.discounts and specifies expected outputs for the main query and the CTE orders.
Queries containing CTEs like the one above (orders and discounts) can be challenging to test and debug because the CTEs contain intermediate calculations. Unit tests at the CTE level reveal issues in those calculations.
As an example of an issue this may catch, the query's orders CTE contains the clause
WHERE transaction_type NOT IN ('refund', 'void')
where refund and void are lowercase. The unit test data contains a row in raw.orders with a transaction_type of VOID (uppercase), which will not be correctly filtered out by the orders CTE WHERE clause.
Because that row is not filtered out, a test of the overall query will fail due to incorrect sums in the outer query. Fortunately, we also specified a unit test at the CTE level that reveals exactly where the error occurred:
======================================================================
FAIL: test_revenue (tests/test_revenue.yaml) (cte='orders')
----------------------------------------------------------------------
AssertionError: Data differs
{'order_id': 1, 'user_id': 1, 'transaction_type': 'complete', 'total': 4}
{'order_id': 2, 'user_id': 1, 'transaction_type': 'complete', 'total': 3}
+ {'order_id': 3, 'user_id': 1, 'transaction_type': 'VOID', 'total': 3}
{'order_id': 4, 'user_id': 2, 'transaction_type': 'complete', 'total': 2}
======================================================================
FAIL: test_revenue (tests/test_revenue.yaml)
----------------------------------------------------------------------
AssertionError: Data differs
- {'user_id': 1, 'gross_total': 7, 'net_total': 6}
? ^ ^
+ {'user_id': 1, 'gross_total': 10, 'net_total': 9}
? ^^ ^
{'user_id': 2, 'gross_total': 2, 'net_total': 2}Being able to break down complex queries with many CTEs helps isolate issues more easily.
Running tests in CI
Unit tests should be quick to run, easy to set up, and enjoyable to write. If you use Spark or DuckDB, setting up unit tests is straightforward because they are easily installed with pip and can run in standalone mode. However, if you're using a SQL engine like BigQuery, Redshift, or Snowflake, it's much more difficult because they are not easily accessible in CI (Continuous Integration) environments.
If you're unable to access your data warehouse from CI, you can leverage a tool like SQLGlot to transpile your existing queries into DuckDB or Spark, so that they can run in an isolated container. If you're using SQLMesh, it has a built-in unit testing framework which transpiles queries automatically and can run unit tests with the YAML format shown above.
Table Diff
As you iterate on new versions of data pipelines, inevitably you'll want to compare your new version's output with the existing one's. Unit tests will catch specific logical changes, but you may want to understand how the data itself is different. Did total revenue change? Does the new version have more rows? Are users still being assigned the correct segmentation categories? Additionally, there may be cases in the actual data that are not represented in the unit tests.
Table diffing, which is implemented by SQLMesh and Data Fold's data diff, are next in line when it comes to validating changes to data.
Table diffing consists of three parts: schema diffs, statistical summaries, and row level comparisons.
- Schema diffs simply compare the columns and types of two tables. It can quickly tell you if any columns were removed, added, or modified.
- Statistical summaries compare things like counts, number of nulls, and average values between two tables.
- Row level comparisons show differences between rows if a matching key is defined.
Here is an example of SQLMesh's table diffing output.
Schema Diff Between 'revenue__prod' and 'revenue__dev':
└── Modified Columns:
├── gross_total (INT -> DOUBLE)
└── net_total (INT -> DOUBLE)
Row Count: revenue__dev: 3, revenue__prod: 2 -- -33.33%
s__user_id s__gross_total s__net_total t__user_id t__gross_total t__net_total
-1 4.0 3.0 NaN NaN NaN
1 2.0 2.0 1 2 3In this example, 'revenue__dev' has changed 'gross_total' and 'net_total' int types to double types. Additionally a strange user '-1' has been added and user '1' has different values.
Audits
The final type of test is the audit or data quality check. Audits are the most commonly implemented kinds of data tests with tools like great expectations, dbt, and SQLMesh.
Audits run after a model has run and validate certain constraints like nullability or uniqueness. Audits can be either blocking or non-blocking, which means that failures can block further execution or just emit warnings.
One of the main benefits of audits is that they can check for upstream data quality issues. For example, if an upstream table has an unidentified issue, a data quality check could catch it because it checks for constraints against actual data.
However, just having audits is not enough to ensure robust pipelines. Unlike unit tests, they are not designed to catch logic differences or edge cases and are more expensive to run. They also only trigger after a model has been materialized which is later than it needs to be.
Here is an example of a SQLMesh audit that has failed.
sqlmesh.utils.errors.AuditError: Audit 'assert_positive_user_ids' for model 'test.revenue' failed.
Got 1 results, expected 0.
SELECT * FROM "revenue__prod"
WHERE "user_id" < 0The audit is a simple SQL query that check if there are any negative user ids. If there are any, it triggers a failure.
Summary
Testing is an essential part of creating maintainable and trustworthy pipelines. By leveraging these three techniques, companies can mitigate risks when making changes to data pipelines. As confidence in these tests increases, the speed and frequency of iteration will increase, allowing your company to be more agile in making trusted data driven decisions.
Please join our Slack community if you would like to chat or learn more about testing data!



