
Are you using dbt and have heard of SQLMesh, but aren't quite sure what it is? This post will teach you the basics of SQLMesh from a dbt user's perspective to help get you up to speed.
Are you using dbt and have heard of SQLMesh, but aren't quite sure what it is?
You are in luck, because this article is for you! We will teach you the basics of SQLMesh from a dbt user's perspective to help get you up to speed.
We talk about the entire data transformation workflow. In each section, we discuss equivalencies between a dbt concept/tool and its SQLMesh counterpart, note any caveats or differences between the two, and list related SQLMesh features and how they can be beneficial.
This is the first of two posts and covers the components used to create a SQLMesh project. Stay tuned for the next post on SQLMesh project execution!
Models
Models are the primary ingredient in a data transformation project, and they are where much of the work happens. This section describes model languages, configuration, and types.
Model languages
SQLMesh supports SQL and Python - you can use either or both in your project.
SQL
Like dbt, the core of SQLMesh is SQL models, the most common language used to transform data.
Much of SQLMesh’s power comes from its ability to understand and parse your SQL, which opens up cool features that we'll talk about in this article.
The first feature is that SQLMesh can translate your SQL queries from one dialect to another, or “transpile” them.
Want to try your queries out locally in DuckDB before running them in your data warehouse? SQLMesh can do that. Want to migrate from one warehouse to another? SQLMesh can help.
Python
Data transformation tools are just one piece of a data engineering system. The data community has embraced Python, and so have we.
dbt executes Python models remotely in the data warehouse, which means you can’t run them in all warehouses or directly interact with the Python runtime. That limits the Python libraries you can use, makes it challenging to debug your code, and slows down development.
SQLMesh natively supports Python models and executes them wherever run is called, so they work with any database SQLMesh supports. There are no restrictions on what can be done or what libraries you use as long as the model returns a Pandas or Spark DataFrame instance.
If the source data is too large to fit into memory, Python models can process the data locally in batches or use pyspark to perform the transformations on an external Spark instance.
Configuration
In SQLMesh, model-level configuration happens at the top of each model’s file in the model definition. This is similiar to dbt's config() jinja function.
This example shows a SQLMesh model configuration from the quickstart guide, specifying its name, kind, cron, and audits.
Example 1: SQLMesh model configuration from the quickstart guide
MODEL (
name sqlmesh_example.full_model,
kind FULL,
cron '@daily',
audits [assert_positive_order_ids],
);Model types
Models come in different flavors - this section gives you a taste of each.
SQLMesh model flavors are called “kinds” and are analogous to dbt “materializations”. The same general types are available, and we discuss each one. A model’s kind is specified in its configuration.
Example 2 shows a minimal SQLMesh SQL model configuration.
Example 2: Minimal SQL model configuration
MODEL (
name <model name>,
kind <model kind>,
cron <model cron>,
);All model configurations require a name. We strongly recommend explicitly specifying the model kind, but it has a default value of VIEW if omitted.
We also recommend specifying the cron parameter, which tells SQLMesh how frequently a model should run. Its default value is @daily. We discuss how SQLMesh schedules model runs in the next post in this series.
A full list of configuration fields available to you can be found here. Some fields, like owner, add metadata to your model, and others, like audits, add additional functionality to the model. We will discuss audits in further detail in the next post in this series.
We now discuss each SQLMesh model kind and its analogous dbt materialization.
View and table models
SQLMesh’s VIEW model kind creates a database view and no physical table, like the dbt view materialization.
SQLMesh’s FULL model kind creates a database table, like dbt’s table materialization.
Both VIEW and FULL model kinds are recreated on each model run.
Incremental models
Incremental models only process data that has been added or modified in the source since the model was last executed.
SQLMesh incremental models come in two different kinds: incremental by time range and incremental by unique key.
dbt incremental models most commonly use the most recent record approach inside the query’s WHERE clause to filter source records by time.
SQLMesh's incremental by time models uses the intervals approach to filtering source records. It keeps track of which incremental intervals have successfully run and which have not or are pending. As such, SQLMesh incremental models can always run in incremental mode and the is_incremental() jinja method is not needed.
SQLMesh provides built-in variables for each time data type, like @start_ds and @end_ds for ds types, which can be used in the WHERE clause and will be substiuted for the correct interval date range. Other available types are date, ts, epoch, and millis.
When defining an incremental_by_time kind, SQLMesh requires the column name for the model’s time column. SQLMesh uses this information to add an additional filter to the query automatically that protects against data leakage.
Example 3: INCREMENTAL_BY_TIME_RANGE model kind with minimal configuration and time-filtering WHERE clause
MODEL (
name blog_example.incremental_model,
kind INCREMENTAL_BY_TIME_RANGE (
time_column ds -- Time column 'ds'
),
);
SELECT
id,
item_id,
ds,
FROM
blog_example.seed_model
WHERE
ds between @start_ds and @end_ds -- Time column 'ds' in WHERE clauseSQLMesh incremental by unique key models are a different kind than incremental by time range. They require that a unique key column (or columns) be specified in the model configuration.
Example 4: Minimal model configuration for the INCREMENTAL_BY_UNIQUE_KEY kind, specifying the name column as the unique key
MODEL (
name blog_example.employees,
kind INCREMENTAL_BY_UNIQUE_KEY (
unique_key name
)
);SQLMesh does not require incremental_strategy configuration. It will automatically use the best strategy for the target DWH.
Ephemeral and embedded
These types enable query reuse across models by injecting the model’s query into other models when SELECTed.
SQLMesh’s embedded model kind is equivalent to dbt’s ephemeral model type.
Seeds
Seeds are CSV files your project loads into the database. In SQLMesh, seeds are a kind of model and are handled like any other model kind.
SQLMesh tracks whether a seed model’s configuration information or CSV data contents are new or have changed and, if so, automatically runs the model and reloads the seed’s data and any tables dependent on it, just like any other model. No separate seed command is needed.
Example 5: Minimal model configuration for the SEED kind, importing the file national_holidays.csv
MODEL (
name blog_example.national_holidays,
kind SEED (
path 'national_holidays.csv'
)
);External
SQLMesh’s EXTERNAL model kind is used to provide SQLMesh with column names and type information about an external data source.
SQLMesh uses this information to extract useful insights from the source, such as column-level lineage. These would be source tables in dbt.
The external source’s schema information is stored in the project’s schema.yaml file. You can create it by hand or use the sqlmesh create_external_models command to generate it for you. Remember to regenerate it when new source dependencies are added to the project.
Example 6: schema.yml file containing the schema information SQLMesh uses for two external data sources
- name: external_db.external_table
description: An external table
columns:
column_a: int
column_b: text
- name: external_db.some_other_external_table
description: Another external table
columns:
column_c: bool
column_d: floatSnapshot
dbt’s snapshots are the mechanism for implementing the Slowly Changing Dimensions Type 2 method.
SQLMesh supports both SCD Type 2 By Time and SCD Type 2 By Column methods. See examples in the docs to see how these approaches compare to see what works best for your project.
Hooks
Catchy hooks make great songs, and sometimes you need them for great models.
SQLMesh pre- and post-hooks are not put in the model configuration, but directly in the model body (before and after the model query, respectively). Each statement must end with a semicolon, and they may use macros.
There are no restrictions on the number of statements a model file may contain, as long as the file contains only one statement with an outer SELECT query. Any statement may contain a nested subquery, but only one statement may solely SELECT.
Example 7: Model containing a pre-query statement that synchronizes the DuckDB WAL with the database and a post-query statement that exports the table to a Parquet file
MODEL (
name sqlmesh_example.full_model,
…
);
-- Synchronize WAL with data in the database
CHECKPOINT;
SELECT
Item_id,
count(distinct id),
FROM
sqlmesh_example.incremental_model
GROUP BY item_id;
-- Write table to Parquet file
COPY sqlmesh_example.full_model TO 'full_model.parquet' (FORMAT PARQUET);Macros
I’m lazy. If I took the time to write some nice code, I want to reuse it everywhere I possibly can. Macros let you inject laziness into data transformation projects.
SQLMesh supports both Jinja and SQLMesh macro systems.
Jinja macro blocks
If a model uses Jinja, the file must be divided into macro blocks. The model query block must be present, and pre-/post-hook statement blocks are optional.
The macro block sections are signaled with text at beginning and end of the different sections:
- Hook statements:
JINJA_STATEMENT_BEGINandJINJA_END - Model query:
JINJA_QUERY_BEGINandJINJA_END
Hooks are specified in a JINJA_STATEMENT_BEGIN block before or after the model query.
The next example shows how we might use Jinja macro blocks in the full_model from the SQLMesh quickstart. It assumes that we have defined Jinja macro functions pre_hook() and post_hook() in the project’s macros/ directory.
The blocks are as follows:
- The first Jinja block uses
JINJA_STATEMENT_BEGINand callspre_hook() - The second block uses
JINJA_QUERY_BEGIN, sets a user-defined variablemy_col, and uses it in the model query - The third block uses
JINJA_STATEMENT_BEGINand callspost_hook()
Example 8: Jinja macro blocks in a modified model from the quickstart guide
MODEL (
name sqlmesh_example.full_model,
kind FULL,
cron '@daily',
audits (assert_positive_order_ids),
);
JINJA_STATEMENT_BEGIN;
{{ pre_hook() }}
JINJA_END;
JINJA_QUERY_BEGIN;
{% set my_col = 'num_orders' %} -- Jinja definition of variable `my_col`
SELECT
item_id,
count(distinct id) AS {{ my_col }}, -- Reference to Jinja variable {{ my_col }}
FROM
sqlmesh_example.incremental_model
GROUP BY item_id;
JINJA_END;
JINJA_STATEMENT_BEGIN;
{{ post_hook() }}
JINJA_END;Jinja macro functions
Jinja macro functions have the same syntax and structure in SQLMesh as in dbt.
User-defined macro functions are placed in the project’s macros directory. For example, this macro function builds a CASE statement from a list of vehicle types.
Example 9: Jinja user-defined macro function that builds a CASE statement
{% macro vehicle_case(vehicle_column, vehicle_types) %}
{% for vehicle_type in vehicle_types }
CASE WHEN {{ vehicle_column }} = '{{ vehicle_type }}' THEN 1 ELSE 0 END as {{vehicle_column}}_{{ vehicle_type }},
{% endfor %}
{% endmacro %}If we called it in a model with {{ vehicle_case(‘vehicle’, ['car', 'truck', 'bus']) }}, it would render to:
Example 10: Rendered output from Example 9 macro function
CASE WHEN vehicle = 'car' THEN 1 ELSE 0 END AS vehicle_car,
CASE WHEN vehicle = 'truck' THEN 1 ELSE 0 END AS vehicle_truck,
CASE WHEN vehicle = 'bus' THEN 1 ELSE 0 END AS vehicle_bus,The last CASE statement in this example ends with a trailing comma. That would generate an error in dbt, but SQLMesh can correctly incorporate it into the query because of its semantic understanding of SQL.
SQLMesh macros
SQLMesh macros use a different syntax than Jinja macros. They are typically more concise because they were custom built for SQLMesh projects.
The primary macro operator is @, as compared to {{ }} in Jinja. SQLMesh macros do not require the file to be differentiated into separate blocks.
The next example shows the definition and usage of a user-defined variable my_col equivalent to the Jinja version in Example 8. The variable is defined in the @DEF statement and referenced in the query as @my_col.
Example 11: SQLMesh user-defined variable equivalent to the Jinja version in Example 8
@DEF(my_col, 'num_orders');
SELECT
Item_id,
count(distinct id) AS @my_col,
FROM
sqlmesh_example.incremental_model
GROUP BY item_idIn SQLMesh, user-defined macro functions are written in Python. Python macros are quite flexible because Python can express more complex logic than SQL.
Python macros can return either strings or SQLGlot expressions that SQLMesh incorporates into the query’s semantic representation. They are defined in a .py file in the project’s macros directory.
This example shows the equivalent of the Jinja macro in Example 9. All Python macros take evaluator as the first argument. The macro defines an empty list cases, adds each vehicle’s statement to it in a loop, then returns the list.
Example 12: SQLMesh user-defined macro function equivalent to the Jinja version in Example 9
from sqlmesh import macro
@macro()
def vehicle_case(evaluator, vehicle_column, vehicle_types):
cases = []
for value in vehicle_types:
cases.append(f"CASE WHEN {vehicle_column} = '{value}' THEN '{value}' ELSE NULL END AS {vehicle_column}_{value}")
return casesThis macro function would be called in a model as @vehicle_case(‘vehicle’, ['car', 'truck', 'bus']]).
Packages
dbt uses packages to add functionality to dbt Core with externally supplied code.
SQLMesh does not have a package manager. Python models and macros allow you to use external libraries and expand code functionality beyond SQL, and you can share macros on Github. Simpler ways to share macros or code are a developing topic.
Platform configuration
DWH platforms are called execution engines in SQLMesh. They are built directly into SQLMesh. Currently DuckDB, BigQuery, Databricks, MySQL, PostgreSQL, GCP PostgreSQL, Redshift, Snowflake, and Spark are supported as of the end of July 2023. Additional connections are planned and are prioritized based on community demand. PRs for new execution engines are also welcomed.
Execution engine configuration is defined within config.yaml at the project's root directory. This example shows the configuration information for a snowflake connection in a YAML project config.
Example 13: YAML configuration for a Snowflake connection
gateways:
my_gateway:
connection:
type: snowflake
user: <username>
password: <password>
account: <account>Futher details on excecution engine configuration and other project-level configuration options can be found here.
Interfaces
Feature lists are cool and all, but if something’s not easy to use I don’t want it!
SQLMesh provides four free, open-source interfaces:
- A command-line interface
- A Jupyter and Databricks notebook interface via notebook
magiccommands - A Python API
- A graphical interface
The graphical interface is accessed via a web browser that runs from your local project. No internet connection is needed or used by SQLMesh, nothing occurs over a network connection, and no information leaves your computer (unless you’re using a remote database connection).
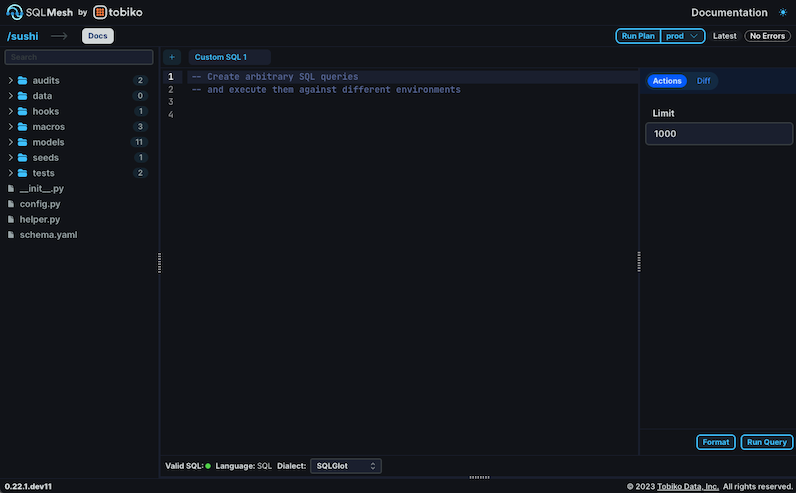
Figure 1: The free, open-source SQLMesh graphical user interface's Editor view
The SQLMesh graphical interface automatically displays column-level lineage information for your project’s models.
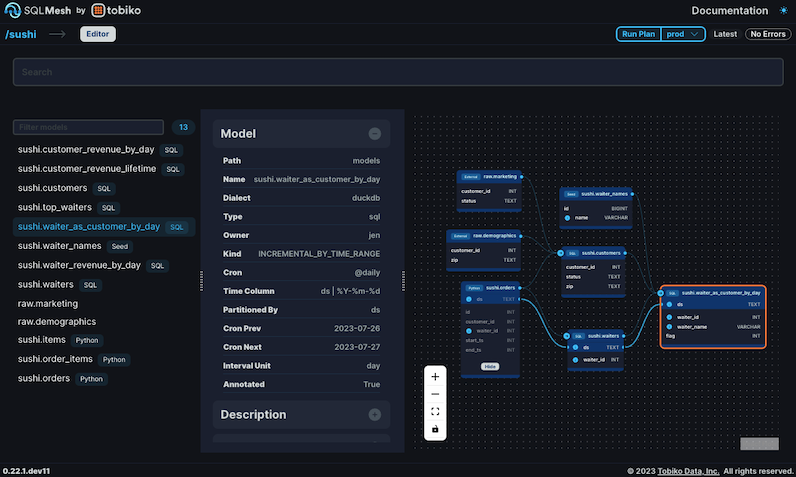
Figure 2: SQLMesh graphical interface Docs view displaying column-level lineage for the sushi example waiter_as_customer_by_day model
Summary - Part 1
This post provided an introduction to SQLMesh models and macros from a dbt user's perspective - we hope it provided an on-ramp to help you understand how SQLMesh works and can be beneficial for your business.
We’d love to hear your thoughts or questions - please join our Slack community!
If you want to get going with SQLMesh, check out the quickstart guide for a brief end-to-end example in each of the three interfaces.
Part 2 in this series will discuss how SQLMesh models are executed and scheduled - stay tuned!
.png)


