
Learn about how SQLMesh saves money with cron and partitions.
How often should my model run? Did my model already run today? What dates has my model been run for?

These are important questions when orchestrating data pipelines but are surprisingly ignored by dbt.
dbt-core has no concept of run scheduling or tracking at all, and dbt-cloud just uses cron to run models at specified times. It doesn't track or check if a model has already run, which leads to developers wasting time doing that tracking and higher data warehouse bills rerunning models that already ran.

Source freshness isn't enough
dbt does have a concept called source freshness but there are a couple of issues with relying on this approach.
- It's a pain to manage if you're using dbt-core (manually managing artifacts).
- You can only define this on sources, not models.
- It only deals with "latest data" which doesn't help with backfills, restatements, or correctness.
- If you have a large interwoven dependency graph, you'll end up refreshing a bunch of models more than necessary anyways. You can't specify that a FULL model refreshes daily when its source runs every five minutes.
In contrast, SQLMesh has a built-in scheduler for executing and tracking model runs. You tell it how frequently each model should run, and SQLMesh ensures it runs on that cadence.
How often should my data model run?
How frequently a model should run depends on two factors: how often the data arrives/ changes and how fresh you need your data to be.
If your data only arrives once a day, there's no reason to run models more frequently than that. Similarly, if a dashboard tracks daily active users, a good starting point is to have the models behind it run at a daily cadence - each day processes the previous day’s users.
Should I run more frequently?
Fresher may seem better, but there are a couple of tradeoffs to consider before simply refreshing your dashboards as frequently as possible.
The first tradeoff is cost. If you refresh your data every 15 minutes but don't really benefit from that level of freshness, you're just wasting money. Depending on how much data you have, the costs can really add up.

The second and arguably more important factor to consider is data completeness. To illustrate this point, consider the following diagram depicting total sales per day:

What happened on September 6th? Did sales have a severe drop? Was there a data outage? Or is it just because the data isn't complete yet and we're looking at a partial day?
Computing data more frequently and exposing partial results to stakeholders can cause confusion and erroneous use of data.
How do you specify how often a model should run in SQLMesh?
SQLMesh leverages cron expressions to define when a model should run. By default, all models have a cron of @daily, meaning they should run every day at UTC midnight. Any legal cron expression in croniter can be used.
MODEL (
name my.model,
cron '5 4 1,15 * *' -- This SQL model should run at 04:05 on days 1 and 15 of each month
)
SELECT *
FROM ...It's important to note that SQLMesh doesn’t “stay on” like a server, continuously monitoring whether model crons have elapsed (although it does integrate nicely with Airflow servers).
Instead, SQLMesh only takes actions when commands are executed. The command that tells the SQLMesh scheduler to determine whether any models should run is sqlmesh run. The scheduler will only execute when you issue that command.
What happens when you run run?
Imagine you have two models, Daily Model (with a cron of @daily) and Hourly Model (with a cron of @hourly), where Daily feeds into Hourly. Every time you execute the command sqlmesh run, it will check which models should run.
The first time you execute sqlmesh run, both Daily Model and Hourly Model will run. If you immediately execute sqlmesh run again, nothing will happen because SQLMesh knows it has not been an hour since the hourly model last ran.
If you execute sqlmesh run after an hour (but within the same day), SQLMesh will see that it's time for Hourly Model to run because it has not yet run this hour and will run it. It will not run Daily Model because it already ran today.
Finally, if you execute sqlmesh run the next day, SQLMesh will run both Daily Model and Hourly Model.
To run the SQLMesh scheduler - you can use a tool like Windows Task Scheduler or Linux’s cron to execute it automatically. You will want to execute it as frequently as your most frequent model cron value so those models don’t run behind schedule. In the example above, you would execute sqlmesh run every hour.
If you have more advanced requirements or are already on Airflow, you can use SQLMesh's Airflow integration.
What dates have been run?
If a model fully refreshes every run, keeping track of the exact dates it has run isn't very useful.
However, if a model is incremental and only processes part of the data every run, knowing the dates it has already run enables sophisticated and scalable incremental loading.
Can you just ignore the issue?
dbt avoids tracking which dates have been run by relying on users to write macros that alternate between two states:
- If the table doesn’t exist, compute the whole history in one shot
- If the table does exist, query it to find the last processed (“maximal”) timestamp and use that to filter the upstream source data.
An example query using this approach looks like this:
SELECT *
FROM raw.sessions
{% if is_incremental() %}
WHERE ts > (SELECT MAX(ts) FROM {{ this }})
{% endif %}Although this approach doesn’t require extra state besides what’s stored in the table, it has drawbacks - especially when operating at scale.
- It assumes that you’re able to load the entire table in one go. At large scales, processing large fact tables may require batching (eg. 1 month chunks) in order to reliably complete.
- The query is more complicated to write and maintain because there are two modes of operation, one for the initial load and one for incremental.
- Custom SQL is often needed to enable faster testing and validation of incremental models during development, eg. only computing 1 day of data.
- You cannot detect or fix data gaps that may occur due to custom scripts or the addition of historical data to an existing model.

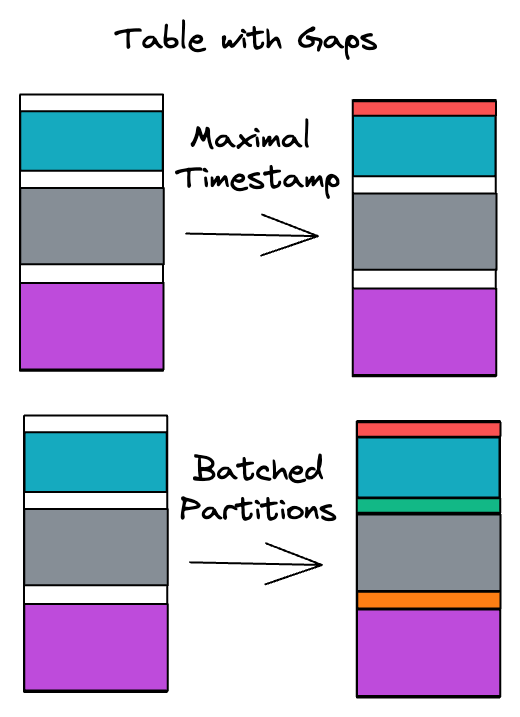
A better approach
It's easier and more scalable for incremental models to be partition/time range aware. Schedulers like Airflow and SQLMesh use this methodology.
Instead of having to worry about two modes when writing and running incremental models, you can just specify a batch’s start and end dates.
SELECT *
FROM raw.sessions
WHERE ts BETWEEN {{ start }} AND {{ end }}With this approach, it's trivial to run multiple batches of your model by chunking intervals. It's also easy to target specific intervals or gaps within your data.
Learn more about how SQLMesh tracks intervals in the SQLMesh incremental models guide
Summary
Through the use of model crons and interval tracking, SQLMesh allows you to schedule complex dependencies with varying frequencies using one command: sqlmesh run.
All of the features described in this post are available for free in open source SQLMesh, and we're looking to make them even more powerful.
We'd love you to join our growing community on Slack.



