
Reflecting on SQLMesh's evolution over the past two years and highlighting the significant performance breakthroughs we've recently achieved.
Starting with SQLMesh release 0.118.0, users should notice drastic improvements in performance. In this post, I’m going to talk about why certain significant performance issues existed in SQLMesh, the historical context behind these inefficiencies, and the improvements we've made to address them.
Get ready for some candid insights into the challenges a small company faces when starting out, the engineering trade-offs made, and the shortcuts intentionally taken.
Historical Context
Everyone knows that starting a new company is hard (and scary), especially when you're up against an established incumbent that has long solidified its position as a staple in your space.
So it’s very important to test your ideas and fail as quickly as possible. Nobody wants to spend years building something only to find out that people don’t care about what you have to offer.
It quickly became apparent that some of the engineering practices considered best at companies like Netflix, Airbnb, and Apple would not apply here. Suddenly, the behaviors that were rewarded in those companies became counterproductive in this new context.
For example, nobody cares about how efficient the implementation would be once we reach scale if we have to pivot and discard the whole thing a month later. At the same time, testing a variety of ideas and features increases our chances of discovering something that people find appealing.
That’s why when we started building SQLMesh in 2022 we were guided by 3 basic principles:
- The fundamental ideas behind the product must be sound and effective at any scale
- Put something in front of users quickly
- The barrier to trying out the product must be as low as possible
Additionally, data transformation is a vast domain. There are so many orchestrators, query engines, SQL dialects, and data modeling techniques that getting the architecture and the implementation just right the first time to accommodate all of them is a fool’s errand.
Therefore, the development process at Tobiko consists of the following phases1:
- Focus on requirements at hand, get something working quickly (prototype)
- Address issues and additional requirements based on user’s feedback (expand)
- Learn more and refactor the implementation once a distinct pattern emerges or existing inefficiencies begin to hinder development velocity and/or user experience (consolidate)
With this context in mind, let’s now discuss some of the runtime-heavy aspects of SQLMesh, as well as decisions we’ve made in the past that haven’t aged well and were revised in the consolidation phase.
SQLMesh Runtime Overview
SQLMesh doesn’t evaluate users' queries directly. All the heavy lifting of query execution is delegated to the underlying query engine or data warehouse provider (e.g., Databricks, Snowflake, BigQuery, etc.).
However, there are still several runtime-intensive processes that occur within SQLMesh itself. For example:
- Parsing raw model definitions
- Fetching and parsing historical model definitions stored in state
- Computing model fingerprints
- Normalizing model queries
- Calculating column-level lineage
- Statically analyzing models' code to determine the macros and variables referenced in them
- Storing new model versions and environments and updating the state of existing ones
On smaller projects (< 50 models) the runtime impact of these various processes is not something that is perceived by a user. When the project has more than 1,000 models, the overhead quickly adds up, making the runtime impact not only noticeable but also detrimental to the user experience.
SQLMesh State: Trade-offs and Pitfalls
SQLMesh is an inherently stateful data transformation solution. SQLMesh relies on persistent state to store model versions, environment metadata, and data intervals.
One problem with state is that it needs to be stored somewhere. Ideally, we want to store this state in an OLTP storage system like MySQL or PostgreSQL, with proper ACID transactions and efficient row-level operations.
Requiring users to set up a separate database instance in addition to their data warehouse significantly raises the barrier to trying out SQLMesh, which goes against one of our principles. We were concerned that users might just give up, unwilling to deal with the additional infrastructure steps.
That’s why we decided to persist the state directly in the data warehouse where users keep and process their data, with the option to configure a separate database for state storage if needed. The idea was to allow users to get started easily, check out SQLMesh’s capabilities, and later switch to a proper OLTP database when they're ready to go to production.
At the same time, since the founding team came from big tech companies, we were quite biased towards Apache Spark and Trino as query engines. We genuinely assumed most large companies already use these tools. This assumption turned out to be wrong, of course, but it nevertheless influenced our product choices.
Unless used with Apache Iceberg, vanilla Apache Spark running on top of Hive Metastore and Parquet files does not support row-level UPDATE operations. This fact significantly limited our options, as the only way to update an existing record in this case is to delete it and insert an updated version. We didn’t want to maintain different state implementations and data models for various engines, so we designed it to work with Apache Spark, knowing that if it works there, it will work with any other engine as well.
Naturally, when there's no way to update individual columns of a record, there's no point in bothering with proper data normalization. For example, snapshot (i.e. versioned model) records were stored as a single large JSON blob with a key. The size of each blob can easily reach tens of kilobytes, which meant that every time we needed to update a timestamp for snapshots demoted from an environment, we had to serialize and transfer megabytes of data, even though a single UPDATE statement with a WHERE clause would have sufficed.
Data Modeling Improvements
To make state operations more efficient, we needed to reduce the size of what was being serialized and updated. The only way to accomplish this was by normalizing the data, which involved extracting record attributes that could change out of the JSON blob.
The first candidate for this optimization was data intervals. Instead of overwriting a snapshot record every time we needed to add an interval, we decided to store intervals in a separate table. This allowed us to simply add a new record to the table each time a new interval was added, without modifying any existing records. If an interval record needed to be removed, we would simply add another record to the table with a special flag indicating that the interval has been removed. These types of records are also known as “tombstone” records.
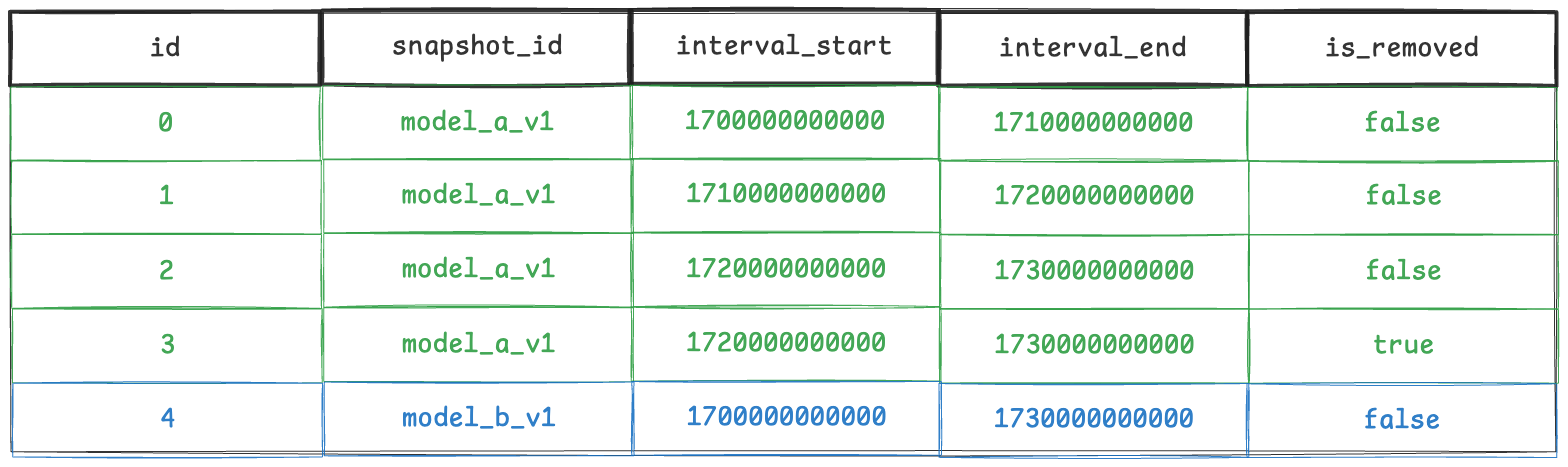
This approach allowed us to simply keep appending new records without needing to overwrite or delete existing ones. It worked really well even with an engine like Apache Spark. The records were also very small, consisting only of a snapshot ID, an integer tuple, a creation timestamp, and a few flags.
The downside is that the intervals table grows uncontrollably. We mitigated this by having a background process that runs with each sqlmesh run prod command, which “compacts” records by merging existing interval tuples and replacing the old records with new merged ones. This way users aren’t exposed to the overhead of the compaction process while developing and iterating on their changes.

Over time, we learned that vanilla open-source Apache Spark is not as prevalent outside FAANG, and cloud providers like Databricks, Snowflake, and BigQuery are much more common. We also discovered that even among Spark users, it was rarely used to store SQLMesh state. This allowed us to exclude Apache Spark from the list of supported engines for state storage and further improve our data model.
Eventually, we normalized the state tables and extracted all mutable attributes, not just intervals, into separate columns. Updates are now made with a single UPDATE statement across hundreds of records, significantly reducing runtime as a result. SQLMesh also takes advantage of indexes when using engines that support them (e.g. MySQL and Postgres).
Having a distinction between mutable and immutable state also unlocked the potential for more advanced caching techniques, which I’ll cover next.
Caching
Other runtime-intensive activities, such as parsing and validating model definitions, parsing JSON blobs fetched from the state, rendering and optimizing queries, etc., are made faster through the extensive use of caching.
There are three primary types of file system caches used by SQLMesh, in addition to various forms of in-memory caching:
- Model Cache: A cache for parsed and validated model definitions loaded from the
models/project folder - Snapshot Cache: A cache for parsed previous model versions (snapshots) fetched from the state database
- Optimized Query Cache: A cache for rendered and optimized model queries, shared between model definitions loaded from the local file system and those fetched from the state database
Cache entries in the Model Cache are invalidated based on the modification timestamps of individual files in the models/ folder. Models for which the source code has changed since the previous load are re-parsed and re-validated.
Decoupling the mutable attributes of the snapshot record from the immutable ones means that we can store the large, immutable portion of each snapshot almost indefinitely in the Snapshot Cache without ever needing to invalidate its entries. Thus, we significantly reduce deserialization overhead and I/O when communicating with the state database, as only a small subset of fields needs to be fetched to reconstruct an up-to-date record on the client side.
The Optimized Query Cache, shared between model definitions on the local file system and those fetched from the state database, ensures consistent cache hits as long as the parsed contents of the model definitions remain unchanged, regardless of their source.
Multiprocessing
Last but not least, SQLMesh now takes advantage of multiple cores when parsing, rendering, and optimizing model queries.
It’s well known that true parallelism can’t be achieved within the same Python process due to Global Interpreter Lock (GIL) (at least before version 3.13). To fully utilize multiple cores in parallel, the solution is to create copies (forks) of the current process and distribute the workload among them. Consequently, using multiple processes introduces additional I/O overhead because the lack of shared memory necessitates less efficient methods for transferring inputs and outputs.
Fortunately, we were able to partially mitigate this issue by having the worker process populate the cache directly, allowing the main process to read from it. This approach also simplified the implementation, as the main process only needs to access the cache, regardless of whether there is an actual cache hit.
Next Steps
The described improvements combined have resulted in a significant reduction in run times, especially for larger projects. Some users have reported a 30-55 second speedup for projects with over a thousand models.
We still have many improvements planned, including more efficient table creation. SQLMesh users can expect the product to become even faster in future versions.
Final Thoughts
Looking back, it’s fascinating to see how external factors and pressures influence design and implementation choices at any given moment. What's known and unknown shifts constantly, so a decision that seems right today might not hold up tomorrow. That’s why successful software products today are like living, breathing organisms, continuously evolving and adapting to their ever-changing environment.
We want you to feel amazing with every interaction you have with SQLMesh. Whether that’s 55 second speedups, or 1, we hope you feel more immersed in the work you love.
Footnote 1 — I didn’t come up with these phases myself. I first learned about them while reading Brian Foote and Joseph Yoder's paper and found them to be a fitting formalization of what the industry has naturally arrived at.



