
dbt's new microbatch incremental models in version 1.9 are a step forward but come with limitations that require advanced handling. They don't have state or history, leading to data gaps and incomplete results.
Earlier this month, dbtTM launched microbatch incremental models in version 1.9, a highly requested feature since the experimental insert_by_period was introduced back in 2018. While it's certainly a step in the right direction, it has been a long time coming.
This delay is in line with dbt's philosophy of treating incremental models as an advanced optimization, rather than a foundational materialization strategy.
In contrast, from the very founding of Tobiko, we designed SQLMesh from the ground up to serve incremental models as a first class experience.
Efficient and accurate data transformations depend heavily on how time is accounted for in the process. That's why we've always believed incremental models should not be reserved for "advanced" use cases, or only applied when queries become slow and expensive. No matter the scale of your project, incremental modeling should always be considered when it fits your data. That means a successful implementation of incremental modeling needs to be easy to use, always correct, and flexible.
Due to fundamental architectural design choices of dbt, the microbatch implementation is very limited. At its core, dbt is a stateless scripting tool with no concept of time, meaning it is the user's responsibility to figure out what data needs to be processed. This ultimately means microbatch is error prone and continues to be most appropriate for only the most sophisticated users.
The initial microbatch implementation automatically filters models based on a user-specified column, lookback period, and temporal batch size (time granularity like day, month, year). There are three ways that this filter can be populated:
- The first run is treated as a full table refresh, so the beginning of the time window will be the model's configured start date and the end of the time window will be now.
- Subsequent runs are considered incremental, so the beginning of the time window will be the temporal batch size + lookback window (e.g., batch size of daily with a 3 day lookback will be 4 days ago), and the end of the time window will be now.
- The user can manually specify start and end when executing the
dbt runcommand.
But by providing only these three options, dbt exposes users to three critical drawbacks.
dbt's microbatch can lead to silent data gaps
Microbatch is set up in a way that if a model ever skips a run, there will be a literal hole in the data.
For example, if a table has 2024-01-01 through 2024-01-03 populated but the model doesn't run until 2024-01-05, 2024-01-04 will forever be missing unless you manually detect and backfill the date. Without state or tracking of what has been done, it's a matter of WHEN this will break, and not IF.
There's no greater pain in data engineering than producing incorrect numbers because of silent data pipeline errors. Imagine a data pipeline with a microbatch model, feeding into a full model that computes monthly revenue. If for some reason the model skips a day, the revenue numbers will have an unexpected drop, leading to immense panic.
Systems that are date-based need to track what has been processed to be reliable. While there are, in theory, two ways for microbatch to address these issues, one is impractical, and the other has significant drawbacks. The first solution is simply to track dates in state - something SQLMesh has supported from the jump - but this runs in direct contradiction to dbt's entrenched scripting / stateless design. The other is to query itself to find what dates have been populated. But here's the kicker - with most warehouses, this can quickly become a very costly operation.
dbt's lack of scheduling requires manual orchestration
Besides not knowing what's been processed, microbatch also doesn't know when things should run. This again puts the burden on the user to keep close tabs on the exact times they need to run models.
For example, take 3 dependent models:
- A (source lands at 1 AM)
- B (source lands at 4 AM)
- C (consumes A and B)
If you run all 3 models between 1AM and 4AM, B and C will be incomplete and incorrect.
Running your project's microbatch models requires extreme precision or manually defining complex rules and selectors to properly orchestrate things. This is a nightmare to maintain and can lead to untrustworthy data.
Mixed time granularities in microbatch can cause incomplete data and wasted compute
As of this post, dbt only supports time granularity at the day level.
Without a concept of time, just running dbt in the default way will cause incomplete data when using models with mixed time granularities.
To illustrate, consider two models:
- A (hourly model)
- B (daily model that consumes A)
If you perform run at 2024-01-02 1:00, model A runs the elapsed hour [2024-01-02 00:00, 2024-01-02 01:00). Model B runs 1 batch of [2024-01-02 00:00, 2024-01-03 00:00).
There are a couple of issues here. The first is that model B is running even though the data is not complete. In general, it is not good practice to publish data that is incomplete because it can cause confusion for consumers who can't distinguish between whether there's a drop in data values, a data pipeline issue, or incomplete data.
Additionally, there is no easy way of tracking which time segments have complete data or not. If runs do not happen every hour, the data gap becomes even harder to detect. Let's say there is a one hour data gap in A and B has already run. You cannot query to check if a date had any data because the data in model B does exist, but it is incomplete.
Although microbatch doesn't yet support anything other than daily, this example highlights the challenges of mixing multiple time granularities without knowing either when things should happen or what has already happened.
Finally, dbt's microbatch approach means that model B is overwritten every hour with incomplete data until the final run, racking up 23 overlapping queries a day, wasting compute and accruing unnecessary costs to you.
Other limitations
Another source of substantial overhead is dbt's restriction to one query per batch. If you're trying to fill 10 years of daily data, this amounts to an astounding 3,650 queries - and it's a challenge to launch so many jobs due to warehouse overhead. It would be more efficient to have a configurable batch size so that you could, for example, launch one job per month, but this is not supported by dbt.
dbt's implementation is sequential. Each day must wait for the previous day to finish before it can run. Incremental models that don't depend on prior state should be much more efficient by merit of being able to run batches concurrently.
SQLMesh - an alternative implementation of time-based incrementals
A number of alternative tools allow you to implement time based incremental modeling. SQLMesh, along with Apache Airflow and Dagster, has both state (understanding what date ranges have been processed) and scheduling (how often and when things should run).
In particular, SQLMesh addresses many of the concerns highlighted in this post.
- It tracks time intervals, preventing data gaps and wasted compute
- It allows you to configure a cron schedule per model, so you can always load things automatically and at the right time
- It has more flexibility, with time interval granularity as precise as 5 minutes, which you can both batch up (to avoid job creation overhead) and run in parallel, and finally,
- It automatically detects when models cannot safely run in parallel, such as those that reference themselves or insert records by unique key.
If you're an existing dbt user and want to leverage SQLMesh's powerful incremental models without a painful migration, you're in luck! SQLMesh can run an existing dbt project, adding various abilities like cron, state tracking, fine grained intervals (5 minutes - hour), batching/grouping, and parallelization.
A dbt model can support both old style maximal timestamp incremental and SQLMesh's incremental by time with the simple jinja configuration {% if sqlmesh_incremental is defined %}:
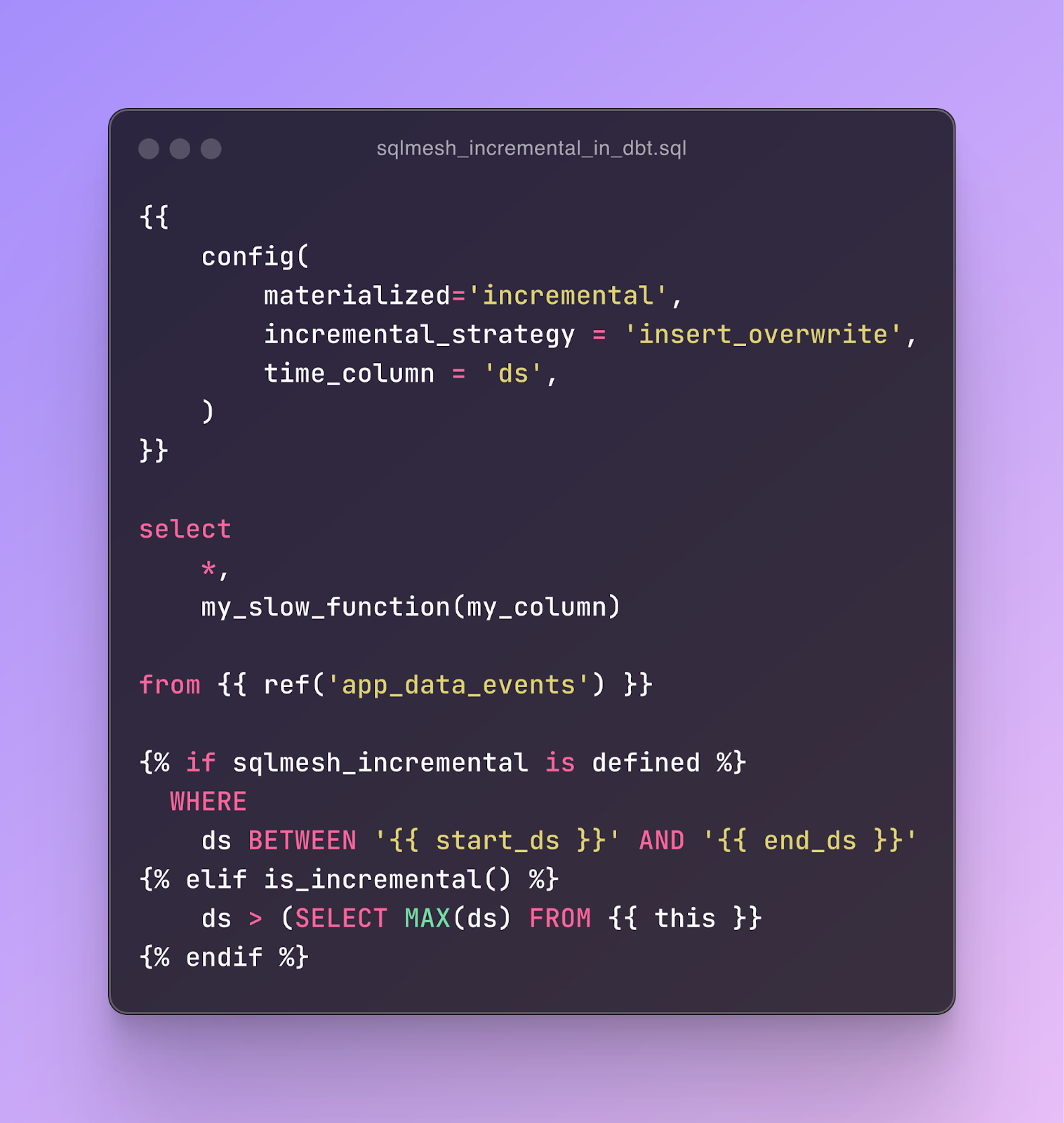
This approach allows you to temporarily run SQLMesh and dbt side by side, enabling a seamless transition.
If you're starting fresh, you can easily get started with a quick pip install.
Here's an example SQLMesh incremental by time model. It specifies a cron schedule of daily UTC and a batch size of 7 meaning it will run up to a week of data in one query.

To run models for a specific time window, you just specify start and end dates for the sqlmesh plan command.

SQLMesh is able to process more than one day per query. SQLMesh executes this INSERT statement based on the previous command:
INSERT INTO "incremental_model__871420228"
SELECT
"source"."a",
"source"."ds"
FROM "source__4283594518" AS "source"
WHERE
"source"."ds" <= '2024-10-02' AND "source"."ds" >= '2024-10-01'If you execute plan again without any dates, it will use the model's entire range (model start date until now). Notice that SQLMesh understands that 2024-10-01 to 2024-10-02 has already been run and will only fill in what's necessary. The source model only processes the latest date because it is not incremental.

SQLMesh executes multiple queries in parallel chunked by the batch size (7 days) based on the previous command:
INSERT INTO "incremental_model__871420228"
SELECT
"source"."a",
"source"."ds"
FROM "source__4283594518" AS "source"
WHERE
"source"."ds" <= '2024-09-07' AND "source"."ds" >= '2024-09-01';
INSERT INTO "incremental_model__871420228"
SELECT
"source"."a",
"source"."ds"
FROM "sqlmesh__default"."source__4283594518" AS "source"
WHERE
"source"."ds" <= '2024-09-14' AND "source"."ds" >= '2024-09-08';
-- More week sized chunks truncatedConclusion
We believe that incremental models should be table stakes for creating and managing efficient data pipelines, and we built SQLMesh with that in mind - to make incremental models flexible, easy to use, and always correct. It bypasses the challenges with data completeness, manual scheduling, and higher costs posed by dbt's offering.
We'd love for you to try SQLMesh. Join our Slack community and book a chat today with us to see a demo and share your experiences and questions on incremental modeling!



