
AI needs robust data management. SQLMesh excels at managed data transformation, allowing us to define our data transformation in SQL, Python, or Jinja and ensuring data quality using audits, unit tests, and intelligent incremental updates.
Effective AI Requires Curated, Trustworthy Data
Successful AI applications are built on a foundation of high-quality data. “Garbage in, garbage out” applies now more than ever. If you feed an AI model incorrect or disorganized data, you get inadequate results (or even hallucinations). If you give the AI access to too little data, it loses its personalized utility. If you give the AI access to too much data, then you risk data leakage and security incidents...and nobody wants that. AI-ready data must be accurate, well-structured, and relevant to our specific needs.
Let's say we want our AI agent to answer questions like “What is the average daily revenue per waiter?”, we need to ensure that:
- The data containing waiter revenues is correctly computed and up-to-date.
- The data is at the right level of detail (e.g., aggregated by waiter per day).
- Errors or inconsistencies (missing values, duplicates, etc.) are handled before the AI sees the data.
SQLMesh excels at data transformation. It allows us to define our data transformation in SQL, Python, or Jinja. We can ensure data quality using audits, unit tests, and intelligent incremental updates.
First we will load a data transformation pipeline in SQLMesh to access the waiter_revenue_by_day table, and then use Spice AI OSS (an open-source AI + SQL engine) running llama3 via Hugging Face to interact with that data using natural language queries.
We’ll use DuckDB for simplicity, and use Spice.ai’s CLI in a local environment.
AI-Ready Data with SQLMesh
SQLMesh can execute data transformation across many different engines. We’ll use DuckDB (a lightweight database and query engine) for a local setup. Our goal is to access and validate the waiter_revenue_by_day table, using raw data about orders, order items, and menu items from a fictional restaurant.
Setup (macOS and Windows)
macOS/Linux
mkdir -p ~/work/sqlmesh-sushi
cd ~/work/sqlmesh-sushi
git clone https://github.com/andymadson/sqlmesh_sushi.gitcd sqlmesh_sushi
python3 -m venv .venv
source .venv/bin/activate
pip install 'sqlmesh[lsp]'Windows PowerShell
mkdir C:\work\sqlmesh-sushi
cd C:\work\sqlmesh-sushi
git clone https://github.com/andymadson/sqlmesh_sushi.git
cd sqlmesh_sushi
python -m venv .venv
.venv\Scripts\Activate
pip install "sqlmesh[lsp]"Download the official SQLMesh VS Code extension from the Extensions: Marketplace:

Select your Python interpreter (you may need to use “Ctrl + P” or “Ctrl + Shift + P” to access the developer menu in VS Code):

Reload your window:

You will see your SQLMesh project scaffolded in your File Explorer window.
The SQLMesh extension provides a lineage tab, rendering, completion, and diagnostics. Click on model top_waiters.sql, and navigate to the lineage tab.

Review the SQLMesh Configuration
Your SQLMesh project’s config.yaml file should contain the following:
gateways:
local:
connection:
type: duckdb
database: sushi-example.db
default_gateway: local
model_defaults:
dialect: duckdbWhat’s in the project?
- models/raw: seed-backed raw tables for the sushi dataset (orders, order items, items, customers). These load the seed CSVs.
- models/…: staging and incremental SQL models that transform to clean, join, and aggregate the raw data into analysis-ready facts and small rollups.
- tests/test_customer_revenue_by_day
Let’s test your configuration. If you don’t receive any errors, then you are good to go!
sqlmesh info
Models: 14
Macros: 0
Initialize Production
After defining the models, we use SQLMesh to plan and apply the changes, which will load the seeds and compute the incremental model.
- Run the project to load the models. In your terminal, run:
sqlmesh plan
.
======================================================================
Successfully Ran 1 tests against duckdb in 0.09 seconds.
----------------------------------------------------------------------
prod environment will be initialized
Models:
└── Added:
├── raw.demographics
├── .... 12 more ....
└── sushimoderate.waiter_revenue_by_day
Models needing backfill:
├── raw.demographics: [full refresh]
├── .... 12 more ....
└── sushimoderate.waiter_revenue_by_day:
[2023-01-01 - 2025-08-19]
Apply - Backfill Tables [y/n]: y
Updating physical layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 14/14 • 0:00:00
✔ Physical layer updated
Executing model batches ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 702/702 • 0:00:26
✔ Model batches executed
Updating virtual layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 14/14 • 0:00:00
✔ Virtual layer updatedSQLMesh analyzes the models and shows a plan of action (creating new tables, etc.). It also runs the defined audits. For our first run, it will create the physical tables and backfill the incremental model from the identified start date.
Let’s change our data and save the change in a virtual data environment we will call “dev”. Then we can review the changes and push the updates to production.
In the orders.csv seed file, add a new row.
27,50,1,1696533690,1696533854,2023-10-05
Run sqlmesh plan dev to save the updated model into a new dev environment.
sqlmesh plan dev
.
======================================================================
Successfully Ran 1 tests against duckdb in 0.05 seconds.
---------------------------------------------------------------------
-New environment dev will be created from prod
Differences from the prod environment:
Models:
├── Directly Modified:
│
└── raw__dev.orders
└── Indirectly Modified:
├── sushimoderate__dev.customer_revenue_lifetime
├── sushimoderate__dev.customers
├── sushimoderate__dev.customer_revenue_by_day
├── sushimoderate__dev.waiter_revenue_by_day
├── sushimoderate__dev.orders
└── sushimoderate__dev.top_waiters
Models needing backfill:
├── raw__dev.orders: [full refresh]
├── sushimoderate__dev.customer_revenue_by_day: [2023-10-01 - 2025-08-19]
├── sushimoderate__dev.customer_revenue_lifetime: [2023-10-01 - 2025-08-19]
├── sushimoderate__dev.customers: [full refresh]
├── sushimoderate__dev.orders: [2023-01-01 - 2025-08-19]
├── sushimoderate__dev.top_waiters: [recreate view]
└── sushimoderate__dev.waiter_revenue_by_day: [2023-01-01 - 2025-08-19]
Apply - Backfill Tables [y/n]: y
Updating physical layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 7/7 • 0:00:00
✔ Physical layer updated
Executing model batches ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 695/695 • 0:00:26
✔ Model batches executed
Updating virtual layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100.0% • 7/7 • 0:00:00
✔ Virtual layer updatedWe can verify our changes by querying DuckDB.
duckdb -ui sushi-example.db
Here’s a breakdown of what DuckDB is storing for our SQLMesh project:

raw- the production views of our versioned physical raw tables in sqlmesh_rawraw__dev- dev environment created views of our versioned physical tables in sqlmesh_rawsqlmesh- project metadata such as snapshots, environments, and _versionssqlmesh_raw- versioned physical tables that raw and raw__dev point tosqlmesh_sushimoderate- versioned physical tables that sushimoderate and sushimoderate__dev point tosushimoderate- production views pointing to physical tables in sqlmesh_sushimoderatesushimoderate__dev- dev environment views pointing to physical tables in sqlmesh_sushimoderate
With our data in place, we can move to the next step: installing Spice.ai OSS.
Introducing Spice.ai OSS for Data-Grounded AI
Spice.ai OSS is an open-source runtime that combines a SQL query engine with an LLM interface. Spice lets you query your data with SQL and AI in one system, regardless of where your data is stored. It can connect to various data sources (databases, data warehouses, files, etc.) and allows AI models to retrieve data and generate answers. The OSS project provides “a unified SQL query interface to locally materialize, accelerate, and query data tables sourced from any database, data warehouse, or data lake.” In practice, this means you can point Spice to data stored in different locations, ask questions in plain English; under the hood, it will federate the query to the appropriate systems and provide the context to the LLM to formulate the answer.
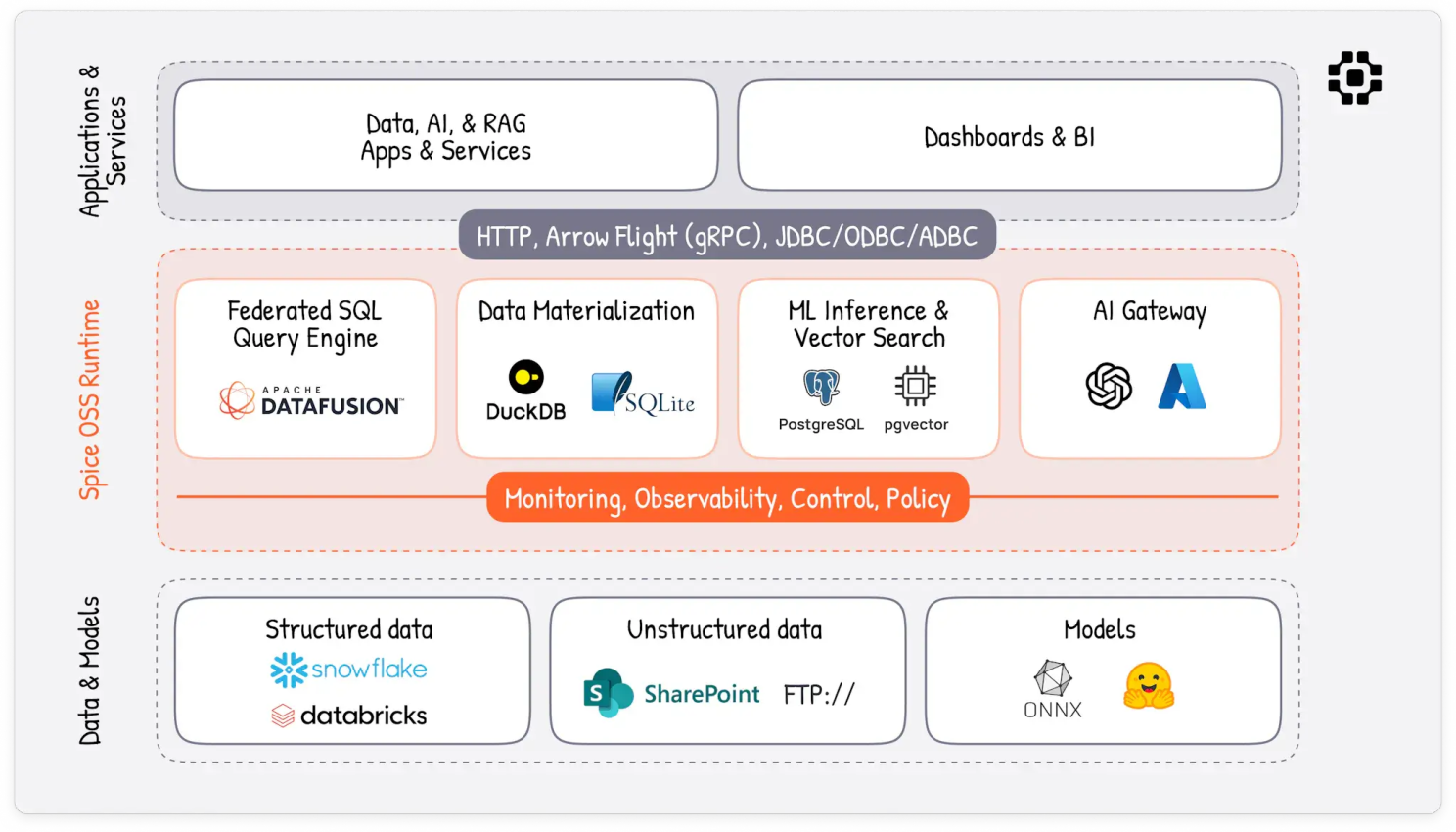
Spice is essentially an “AI-native” data engine. It uses Apache DataFusion and Apache Arrow for querying data, and integrates with LLMs to interpret questions and provide answers. The LLM is given access to the data (through what Spice calls “tools” as seen in our spicepod.yaml). This enables the LLM to stay grounded in the relevant data.
Spice keeps data accessible, isolated and secure. We identify specific data that our LLM can access, and ensure that no sensitive information is accidentally provided by being deterministic in our SQLMesh data transformation, and intentional with out spice configuration. For instance, the Marketing Team may need an LLM that interacts with the customer_lifetime_value table, while Sales may need to know the waiter_revenue_by_day. It’s easy and lightweight to deploy multiple instances of Spice and personalize the configuration of each one to meet the specific use case. This makes data exploration much more accessible, especially for non-SQL experts, while still ensuring the answers are based on real data.
We will use Spice.ai to load the waiter_revenue_by_day data and interact with it. We’ll run Spice locally via its CLI.
Setup Spice.ai OSS
Let’s get started.
Create a new folder, and install the Spice CLI. Spice provides an installer script and Homebrew option.
# Create a new folder, outside of your SQLMesh project
mkdir sqlmesh_spicepod
cd sqlmesh_spicepod
# On macOS
curl https://install.spiceai.org | /bin/bash
# with Homebrew:
brew install spiceai/spiceai/spice# On Windows
iex ((New-Object System.Net.WebClient).DownloadString("https://install.spiceai.org/Install.ps1"))Initialize the project
spice init sqlmesh_spicepodspice init creates a spicepod.yaml inside your new spice folder. You can think of a spicepod like a project or a manifest. It gives our app instructions.

Verify the runtime installation
spice version
CLI version:
v1.5.2
Runtime version:
v1.5.2-build.f3cf260+models.cudaUpdate the spicepod.yaml with our dataset, model, and instructions:
version: v1beta1
kind: Spicepod
name: sqlmesh_spicepod
datasets:
- acceleration:
enabled: true
refresh_check_interval: 1d
refresh_mode: full
from: duckdb:sushimoderate.waiter_revenue_by_day
name: waiter_revenue_by_da
params:
duckdb_open: C:\Users\andym\sqlmesh_tutorials\sqlmesh_sushi\sushi-example.db # Path to DuckDB file
models:
- name: llama3
from: huggingface:huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF
files:
- path: Llama-3.2-3B-Instruct-Q4_K_M.gguf
params:
hf_token: ${ secrets:SPICE_HUGGINGFACE_API_KEY }
tools: auto
system_prompt: |
query the dataset using tool calls and return results. For instance, to find the average revenue for each waiter, you would use the following tool call: {"name": "sql", "parameters": {"query": "SELECT waiter_id, AVG(revenue) AS avg_revenue FROM waiter_revenue_by_day GROUP BY waiter_id ORDER BY waiter_id"}}Let’s break down our spicepod.yaml configuration:
datasets:
- acceleration: # Local acceleration to speed up queries
enabled: true # Turn acceleration on
refresh_check_interval: 1d # Re-check the source every 1 day
refresh_mode: full # Full reload on each refresh (no incremental append)
from: duckdb:sushimoderate.waiter_revenue_by_day # Source table
name: waiter_revenue_by_day # How this table is exposed inside Spice
params:
duckdb_open: C:\Users\andym\sqlmesh_tutorials\sqlmesh_sushi\sushi-example.db # Path to DuckDB filedatasets are the tables that we give our AI model access to. In this example, we are giving the AI access to waiter_revenue_by_day. Spice has the ability to intelligently cache data to make retrieval lightning fast. This becomes more important as datasets grow.
models:
- name: llama3
from: huggingface:huggingface.co/bartowski/Llama-3.2-3B-Instruct-GGUF # HF model to run locally
files:
- path: Llama-3.2-3B-Instruct-Q4_K_M.gguf
params:
hf_token: ${ secrets:SPICE_HUGGINGFACE_API_KEY } # Read HF token from your secret store
tools: auto # Give the model access to Spice tools (SQL, schema, etc.)
system_prompt: | # Default guardrails and instructionsmodels - we will use the bartowski/Llama-3.2-3B-Instruct-GGUF. (This is a quantized model that compresses the size of the original. If you’d like to use the original model, locate it here and apply for access).
tools give our model access to the data.
system_prompt lets us provide overarching instructions applied to each individual prompt.
hf_token - Create a new token on huggingface.co, and add the token to a .env file in your project folder.

In your terminal, start the Spice runtime.
spice run
Keep the Spice runtime terminal running, and open a new terminal. In your new terminal, validate the connection to DuckDB.
spice sql
Spice.ai OSS CLI v1.5.2
Welcome to the Spice.ai SQL REPL!
Type 'help' for help.
show tables; -- list available tables
sql> show tables;
+---------------+--------------+-----------------------+------------+
| table_catalog | table_schema | table_name | table_type |
+---------------+--------------+-----------------------+------------+
| spice | runtime | task_history | BASE TABLE |
| spice | public | waiter_revenue_by_day | BASE TABLE |
.+---------------+--------------+-----------------------+------------+
Time: 0.064014 seconds. 2 rows.We have access to our waiter_revenue_by_day table from SQLMesh! Now let’s interact with our llama-3 agent.
Open a new terminal, and launch the AI chat function:
spice chat
Spice.ai OSS CLI v1.5.2
Using model: llama3
chat> what is the average revenue and total revenue for each waiter_id?
The average revenue and total revenue for each waiter_id are:
| waiter_id | avg_revenue | total_revenue |
| --- | --- | --- |
| 7 | 401.42 | 2071.13
| 5 | 333.70 | 1668.5
| 1 | 253.67 | 1268.3
| 0 | 222.81 | 891.2
| 3 | 281.83 | 1127.3
| 4 | 252.23 | 1008.9
| 9 | 168.50 | 842.5
| 6 | 109.53 | 474.6
| 8 | 175.36 | 876.84
| 2 | 223.78 | 1068.9
Time: 138.82s (first token 30.01s). Tokens: 2597. Prompt: 2419. Completion: 178 (1.64/s).Spice has a SQL REPL (spice sql) where we can directly run SQL ourselves to double-check the chatbot response:
spice sql
Spice.ai OSS CLI v1.5.2
Welcome to the Spice.ai SQL REPL!
Type 'help' for help.
show tables; -- list available tables
sql> SELECT
waiter_id,
AVG(revenue) AS avg_revenue,
SUM(revenue) AS total_revenue
FROM waiter_revenue_by_day
GROUP BY waiter_id
ORDER BY waiter_id;
+-----------+--------------------+--------------------+
| waiter_id | avg_revenue | total_revenue |
+-----------+--------------------+--------------------+
| 0 | 222.8175 | 891.27 |
| 1 | 253.67 | 1268.35 |
| 2 | 213.782 | 1068.91 |
| 3 | 281.83250000000004 | 1127.3300000000002 |
| 4 | 252.22999999999996 | 1008.9199999999998 |
| 5 | 333.706 | 1668.53 |
| 6 | 109.53599999999999 | 547.68 |
| 7 | 401.428 | 2007.1399999999999 |
| 8 | 175.36999999999998 | 876.8499999999999 |
| 9 | 168.504 | 842.52 |
+-----------+--------------------+--------------------+
Time: 0.0211941 seconds. 10 rows.Conclusion
You did it! You powered your AI chatbot with curated, managed, high-quality data. We prepared a dataset for using SQLMesh and then leveraged Spice.ai OSS to interact with that data. Here are the key takeaways:
- Data Preparation: AI is only as good as the data behind it. We used SQLMesh to transform raw operational data (orders and items) into a clean, aggregated form (daily revenue by waiter). SQLMesh’s features like seed models and incremental transforms helped ensure the data is accurate, up-to-date, and efficiently processed, while audits and proper schema design enforced data quality (no missing or duplicate entries). This addresses the fundamental “data requirements” for AI – having the right data at the right granularity, cleansed and ready for analysis.
- AI Integration with Spice AI: With Spice, we connected an LLM to our structured data. Spice provides a unified environment where the AI model can query the data and compose an answer. We configured a local Spice app to read our DuckDB table and llama-3 model to handle the questions. The model, empowered with the ability to run SQL (thanks to Spice’s tooling), was able to compute the answer to a natural language question by actually retrieving and calculating the relevant numbers from the database. This approach ensures the AI’s answers are grounded in factual data rather than guesses.
- Local, flexible setup: We used a local DuckDB and local Spice CLI, which made the demo simple. In a real-world scenario, you could plug in other databases (e.g., Snowflake, BigQuery) by adjusting SQLMesh’s config and Spice’s connectors (Spice can connect to many data sources like Postgres, Snowflake, etc., in addition to files). The same principles apply: define your transformation in SQLMesh, run it to get the data ready, then point Spice to the resulting tables. Spice can even be containerized for deployment, but the local CLI approach we showed is great for development and testing.
By combining robust data engineering with powerful AI tools, we enable insights like “Who are my top-performing waiters?” or “What’s the trend of revenue over the last week?” to be obtained quickly and confidently. The AI can handle the heavy lifting of querying and explaining, but it relies on the solid data foundation we built with SQLMesh.
Happy Engineering!
{{banner-slack}}



